

Inside Git: The Two Concepts Every Developer Should Understand
A simple mental model of Git built on copying code and tracking changes


If I had to explain why Git is so powerful in the simplest way possible, I’d boil it down to just two things:
It makes copies of code easily
It tracks changes
That’s it.
But behind these two simple ideas lies the foundation of modern software development.
Why Making Copies of Code Matters
At first glance, “making copies” sounds trivial. But in software development, it’s everything.
Modifying code directly is destructive.
Modifying a copy is safe.
This one distinction changes how we build software.
When you want to add a new feature, the workflow becomes:
Create a copy
Modify it
Test it
Review it
Commit the changes back to the original
Simple. Controlled. Safe.
#1 Making Mistakes Becomes Cheap
Mistakes are inevitable. But Git makes them cheap.
If something goes wrong:
You can discard your modified copy instantly
You can recreate it from the original with a single command
Even better, you don’t have to throw everything away.
You can go back to a specific checkpoint in your code:
Copy A
→ Checkpoint 1
→ Checkpoint 2
→ Checkpoint 3These checkpoints are called commits.
They act like save points in a game—you can always go back.
#2 Copies Enable Decoupling
Copies don’t just make things safer—they make things organized.
They allow different parts of development to happen independently without interfering with each other.
A typical workflow might look like this:
Production Copy – Stable code used by real users
Develop Copy – Where ongoing development is consolidated
Release Copy – Prepared for upcoming releases
Feature Copy – For building new features
Bugfix Copy – For fixing issues
Hotfix Copy – For urgent production fixes
Without this separation, it would be chaos:
Unfinished features would reach users
Untested code would mix with stable code
Bugs would be impossible to reproduce
The codebase would constantly be unstable
Copies create order out of chaos.
What About Tracking Changes?
If making copies is one half of Git, tracking changes is the other.
And it’s just as important.
Tracking changes builds a repository
And a repository which makes making copies possible.
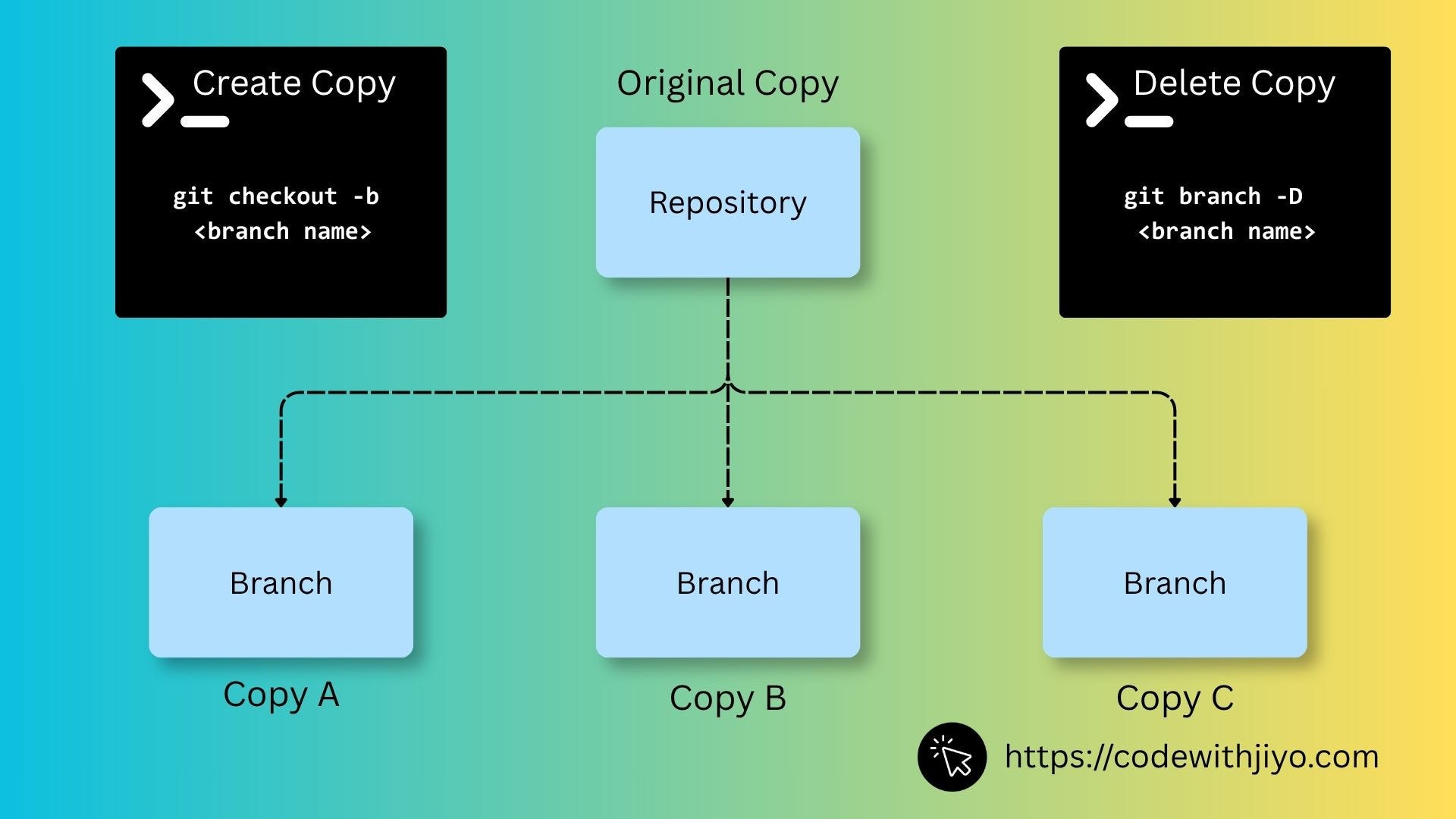
These copies are called branches.
The Lifecycle of a Repository
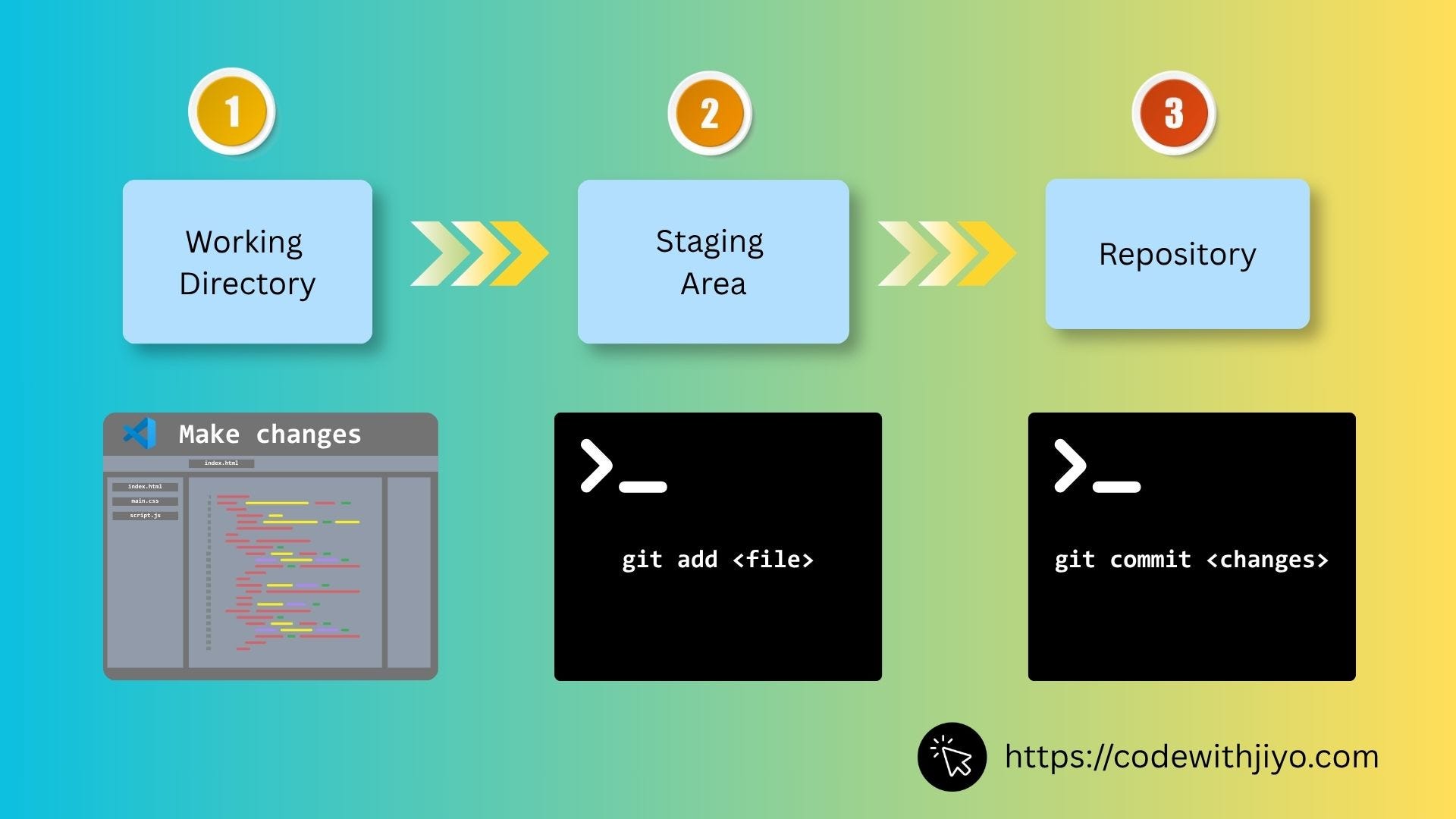
Every repository follows a simple loop:
You make changes
You choose which changes to keep
You commit those changes to a repository
Then you repeat
Over and over again.
This cycle is powered by change tracking.
Why Tracking Changes Matters
Without tracking:
You wouldn’t know what changed
You couldn’t separate tested vs untested code
Every version would blur into one
With tracking:
Every change is recorded
Every version is recoverable
Every decision is intentional
Tracking gives structure to your work.
Final Thoughts
Git isn’t just a tool—it’s a system built on two powerful ideas:
Copying enables safety and flexibility
Tracking enables clarity and control
Together, they allow developers to move fast without breaking everything.
And without them?
It would be pure chaos.